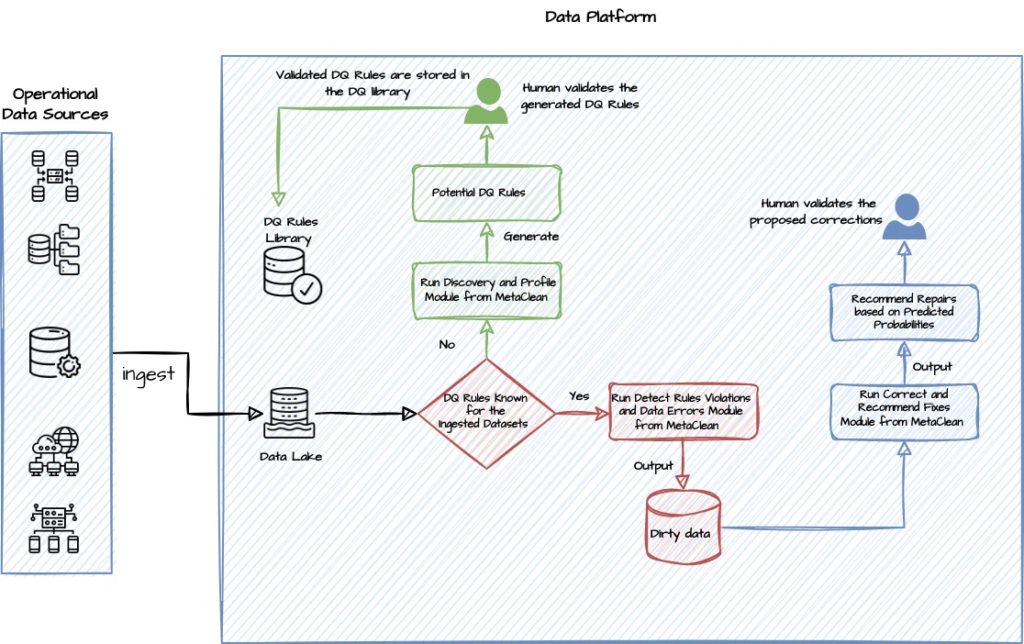
Data quality is one of the most challenging problems in data management, since dirty data often leads to inaccurate data analytics results and incorrect business decisions. Poor data across businesses and governments are reported to cost millions of euros a year. Multiple surveys show that dirty data is the most common barrier faced by data users, including AI engineers. Not surprisingly, developing effective and efficient data cleaning solutions is challenging and is rife with deep theoretical and engineering problems.
We Introduce MetaClean a statistical inference engine to impute, clean, and enrich data. It is composed of a suite of modules with an open source backbone that meant to be assembled to build deployable data quality workflows. MetaClean leverages available or generated data quality rules, value correlations, reference data, and multiple other signals to build a probabilistic model that accurately captures the data generation process, and uses the model in a variety of data curation tasks. It is not a one size fits all hands-off solution.